
SpeakIn 是一款专为 Windows 设计的桌面语音输入工具 按下全局热键直接说话,语音在后台实时转为文字,自动输入到当前光标所在的窗口 全程无需切换窗口,不打断工作流
如果你每天需要向 Claude、ChatGPT、Cursor 等 AI 输出大量文字 比如写需求描述、架构设计、Bug 分析或产品想法 打字很容易成为效率瓶颈,而且让人疲劳
SpeakIn 解决了这个问题
- 速度极快,语音输入可达 300+ 字每分钟,是打字的 4-5 倍
- 心流体验,说话比打字自然,像产品经理一样直接对 AI 下达指令,不需要逐字敲击
- 保护健康,减少键盘敲击,保护腱鞘和颈椎
- 成本极低,利用大厂免费的 ASR 额度,日常使用几乎零成本
核心功能速览
- 多供应商支持,原生支持火山引擎豆包(推荐)、阿里云百炼、千问等语音识别大模型
- AI 二次优化,接入任何兼容 OpenAI 格式的大模型,把口语化文字自动润色、翻译、纠错或格式化
- 双音频源,既支持麦克风输入,也支持录制系统正在播放的声音
- 智能静音与过滤,过滤环境噪音,连续静音 6 秒自动停止,30 秒无声音自动取消
- 系统级悬浮窗,桌面底部半透明浮层,实时显示转写状态,不遮挡主界面
语音识别服务商配置
初次安装进入软件后,点击右上角设置,在「识别」选项中配置 ASR 服务商 软件默认首推火山引擎豆包,同时支持阿里云百炼和千问大模型
下面是免费凭证获取和配置流程
方案一 火山引擎豆包配置指南(默认推荐)
它的识别速度和准确率目前体验最好,你需要一个火山引擎账号来获取免费的 API 凭证
1. 注册并实名认证
前往 火山引擎官网 注册账号,完成实名认证 必须认证才能领取免费试用额度
2. 创建应用并选择能力
- 打开 火山引擎语音控制台 并登录
- 点击页面上的「创建应用」
- 应用名称和简介随便填,比如填 SpeakIn
- 重点来了,在接入能力列表里,必须勾选下面两项
- 豆包流式语音识别模型2.0 小时版
- 豆包录音文件识别模型2.0 标准版
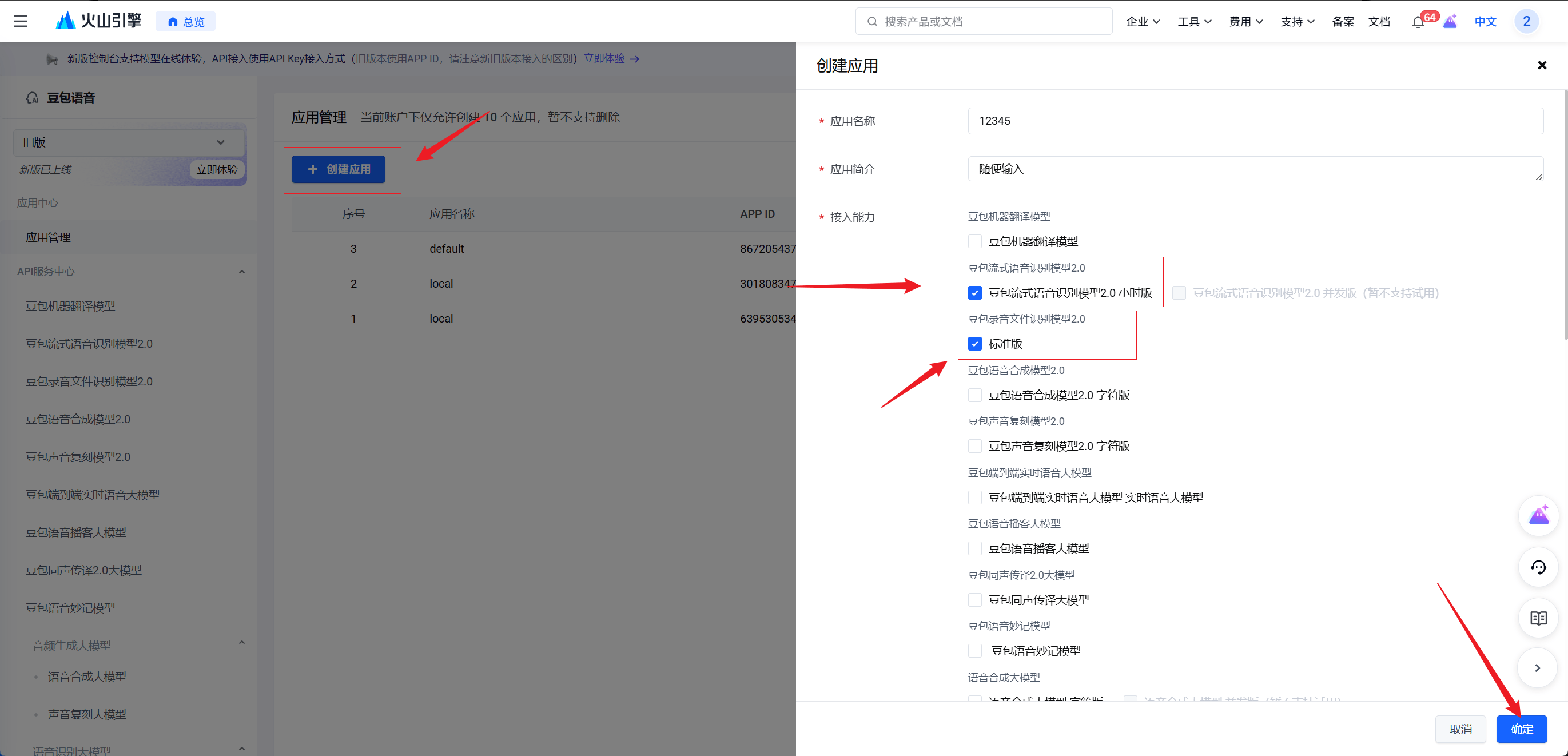
- 点击创建
3. 获取并填写凭证
- 应用创建成功后,进入应用详情页,或者在左侧导航栏点击刚开通的豆包流式语音模型
- 找到并复制 APP ID 和 Access Token
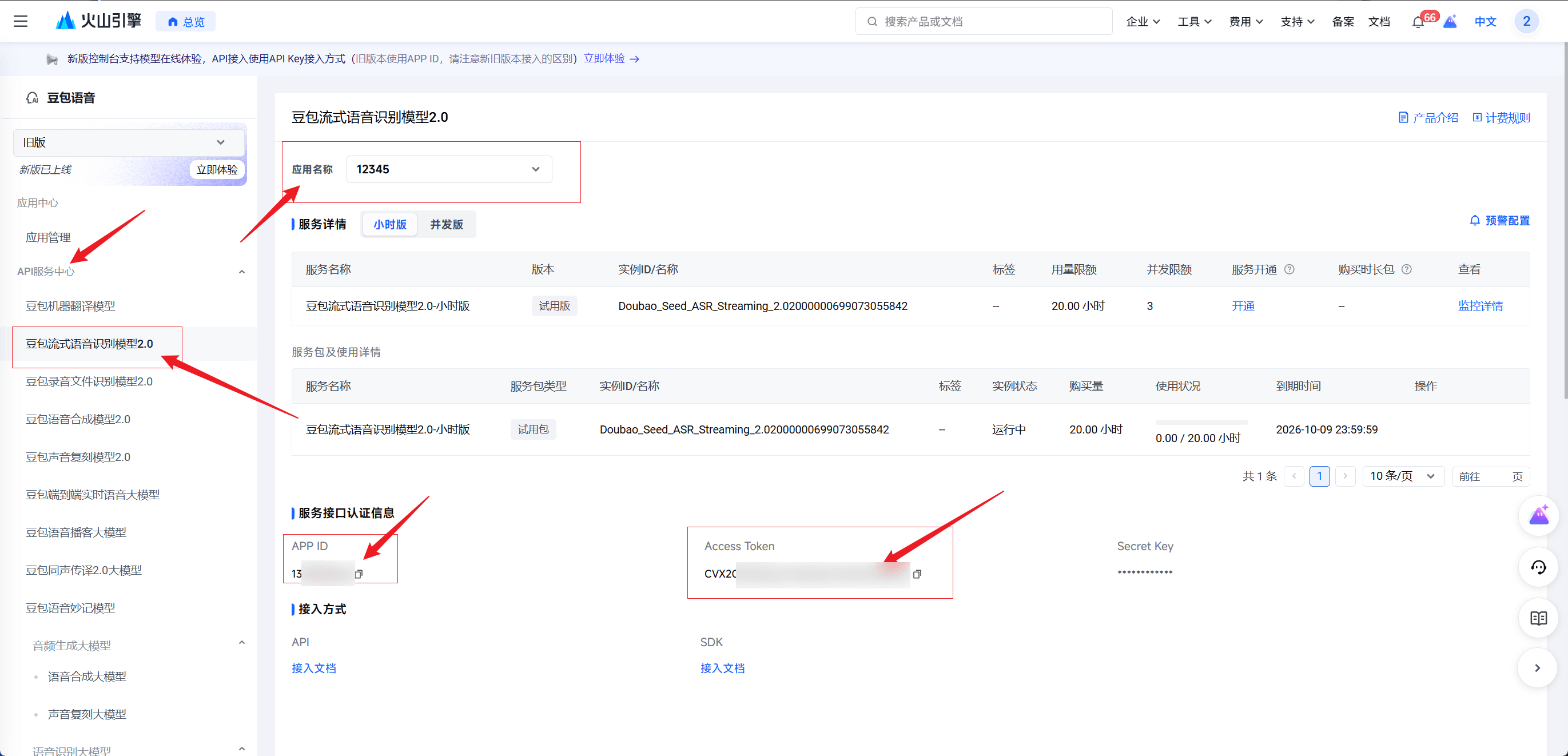
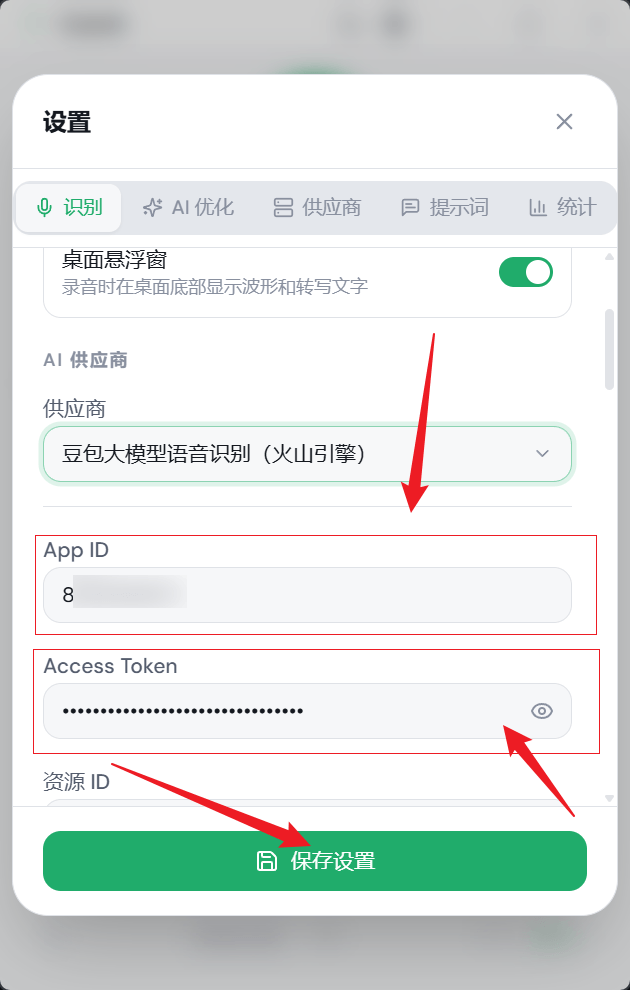
- 回到 SpeakIn 软件的设置页 -> 识别 -> 豆包配置区,把这两个值粘贴进去
- 点击底部的保存设置
新用户首次开通火山语音服务都会赠送免费额度,每个应用 20 个小时 用完可以重新创建应用,会再赠送 20 个小时
方案二 阿里云百炼千问配置指南
如果你想用阿里云的服务,在 SpeakIn 中可以无缝切换 阿里云语音服务目前分「百炼 DashScope」和「千问 Qwen」两条线 但在 SpeakIn 中它们共用同一个阿里云账号和 API Key,操作逻辑完全一样
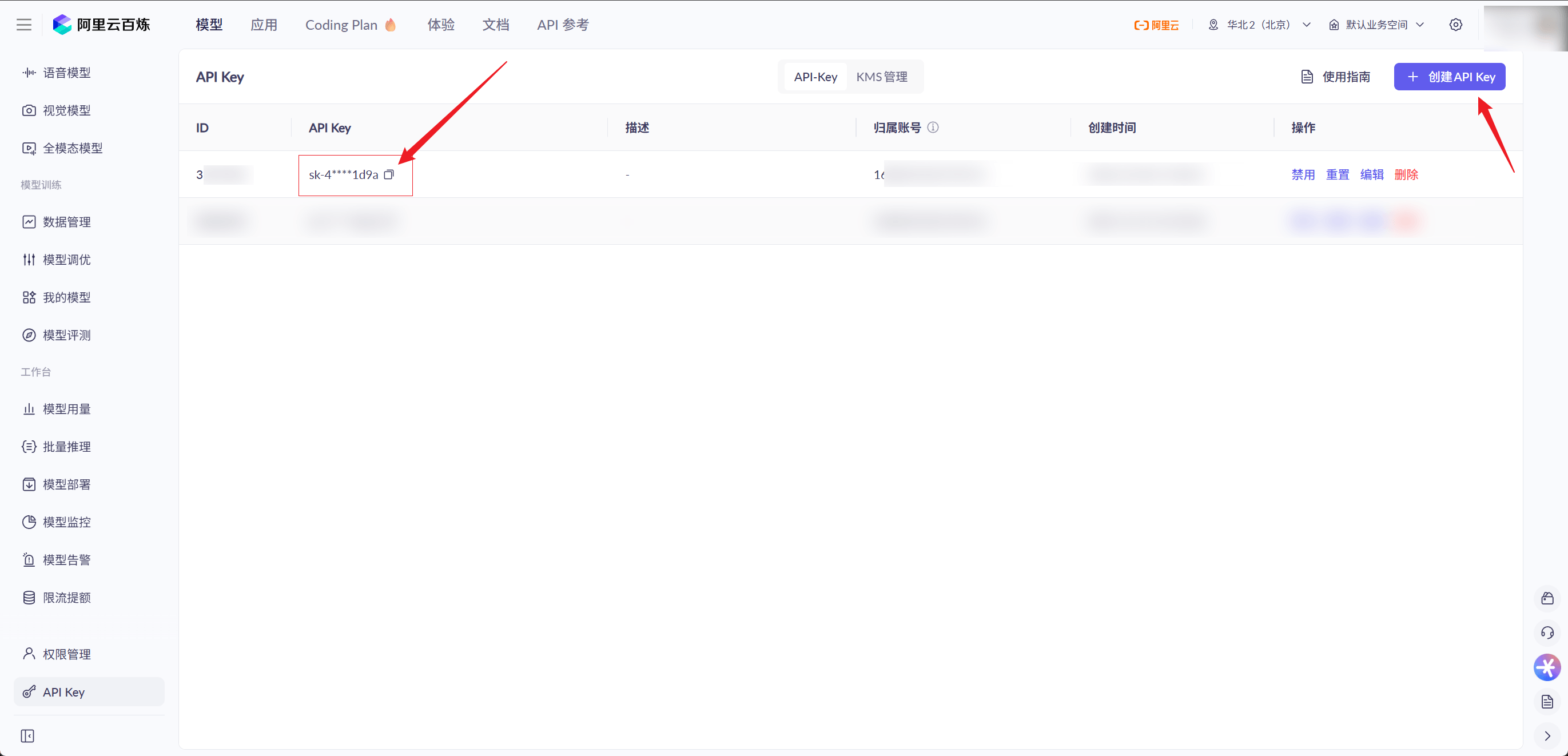
1. 获取 API Key
- 访问登录 阿里云百炼 API Key 管理控制台
- 点击右上角的「创建 API Key」按钮
- 复制生成好的 API Key
2. 在软件中填写凭证
- 回到 SpeakIn 设置页 -> 识别,把 ASR 服务商切成 百炼 Paraformer 或 千问 Qwen3 ASR
- 将复制好的 API Key 粘贴进对应的输入框
- 点击底部保存设置
💡 附 百炼与千问的区别 在软件中填写相同 API Key 就能用这两个,但它们底层能力和侧重点不同
- 百炼 DashScope 阿里云传统的语音识别服务,内置 Paraformer Gummy 等模型,采用二进制直接发送的流式协议,延迟极低,带宽开销极小,适合日常快节奏高频使用
- 千问 Qwen 基于千问大模型的新一代 ASR,走 OpenAI 兼容协议,多语种能力极强,支持 30 多种语言及方言识别,自带情感感知,是大模型路线的未来方向
日常中文语音输入用百炼足够轻巧高效 如果对多语种或方言有更强需求,可以切千问试试
软件进阶设置指南
SpeakIn 有非常丰富的自定义能力 除了刚配好的语音识别,设置面板中还有下面这些核心功能
1. 识别设置
- 音频来源 支持麦克风和系统声音,系统声音主要用来提取正在播放的视频或播客的文字
- 热键与模式 默认快捷键
Ctrl+Shift+V,支持「切换模式」按一次开始再按一次停止,或「按住模式」按住说话松手停止 - 输出方式
- 模拟键入(默认),像真实键盘一样逐字打出,兼容性最强,适用于所有编辑器和网页
- 粘贴输入,速度最快,利用剪贴板直接
Ctrl+V,适合需要保留多行格式场景 - 仅显示,只在 SpeakIn 悬浮窗显示文字,不输出到其他软件
- 文本替换 可以自定义替换规则来修正 ASR 常见误识别,留空表示直接删除该词,规则即时保存,按“原文更长优先”执行防误伤
2. AI 优化与供应商
SpeakIn 不仅能把声音转成文字,还能直接把文字洗成你想要的格式
- 供应商管理 在「供应商」标签页中可以添加任意支持 OpenAI 格式或 Gemini 协议的 API,比如 DeepSeek、Claude、GPT-4,API Key 保存在系统原生安全密钥链中,极其安全
- 开启 AI 优化 回到「AI 优化」标签页开启该功能,选择配好的大模型并挑一个提示词,每次语音识别完毕,软件会在后台自动调取大模型做二次处理,再将优化后的结果输出到屏幕上
3. 提示词库
软件内置了超过 20 款实用 Prompt,分为几个大类
- 润色 把随意口水话转成正式书面语
- AI 对话 把口述转为清晰的 Prompt 结构、Bug 描述或需求文档
- 开发者专属 自动格式化 Git Commit Message、代码注释或 PR 描述
- 翻译 识别中文,直接输出对应的英文繁体中文
你可以根据需要自由新建和编辑提示词,只要模板中包含 {{text}} 占位符就行
4. 统计与隐私
- 软件内置数据看板,记录录音时长、输入字数以及为你节省的时间,按手打 50 字每分钟估算
- 绝对隐私,SpeakIn 不收集不存储不上传任何用户数据,录音和文字仅在本地处理,直接发给你自己配置的 ASR 和大模型厂商
想探索更多高阶用法,或者不想自己写 AI 优化提示词,可以直接访问本站整理的 提示词库 里面收集了大量现成好用的 Prompt,欢迎直接复制使用